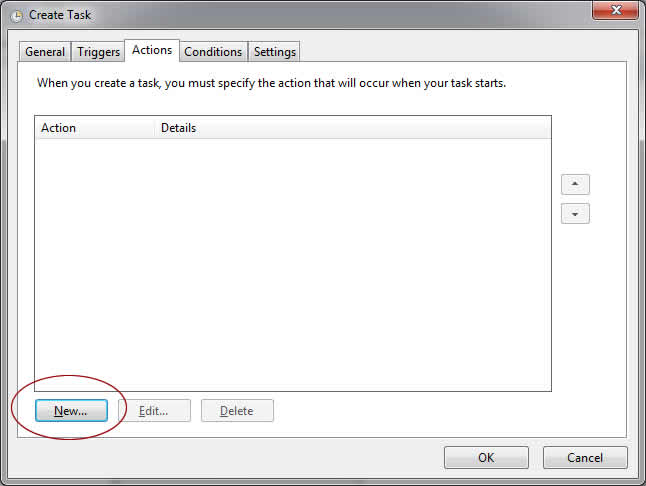
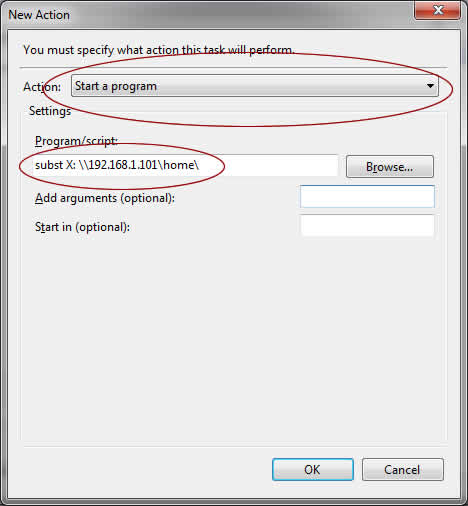
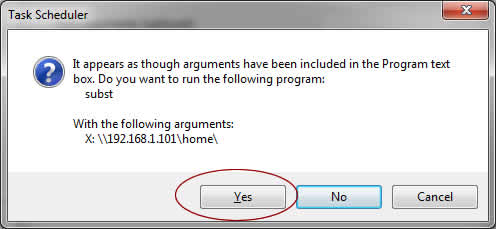
I bought a HP LaserJet 1000 printer back in 2001. Still Loving it! The running cost is low and the output quality is great. It is still working great after running for 13 years! Its quality even out beats my brand new Samsung LaserJet! HP LaserJet 1000 is a almost-perfect printer except that HP no longer supplies the right driver for modern operating system. Long story short, if you are a Windows 7/8 (64-bit) user, HP wants you to dump your fully working printer to the landfill and get a new one.
To be honest, I don’t see any reason why I should buy a new printer just because the driver is no longer available. The core part of the printing technology hasn’t been changed for many years. In the other words, if I get a new printer, I will expect to get the same results (may be slightly better) in terms of printing quality. That’s it. Anyway, if you have few hours to spend, you may want to follow this tutorial to give your printer a new life.
Normally, many printers share similar chips and processors such that if the driver of this model is not available, you can still use the drivers from other models. However, this printer is special. It does not have its own processor and it relies on the operating system to process the print job first before sending to it. That’s why driver is very important in this case.
I have googled for a solution for a long time because I don’t want to send this almost-perfect printer to landfill, and I don’t want to go back to Windows XP either. Unfortunately, most solutions I found online either do not work or don’t make any scenes to me. Here are some highlights:
Solution 1: Attach the printer to Windows XP 32-bit. Share the printer with Windows 7 64-bit through network.
Comments: No it won’t work. Windows 7/8 keeps asking for a driver, which I don’t have one.
Solution 2: Install a Windows XP 32-bit virtual machine (VM) in your Windows 7 64-bit. In the VM, install a software to monitor a folder and print all .PDF files automatically. At the same time, print your documents to PDF in Windows 7 and save the files in that folder.
Comments: Don’t you think it is too complicated?
Solution 3: Install the printer driver in XP mode.
Comments: No it won’t work!
Solution 4: Stick with Windows 7 32-bit
Comments: No way! I want to use more than 4GB of memory.
So after spending months and months and months to trial and error, I finally found a working solution. In fact, my solution is pretty simple. I attach my printer to a Linux box and share it on the network, i.e., I make my HP LaserJet 1000 to be a network printer. Now I can print from the following systems:
- Windows 7/8 32-bit and 64-bit
- OS X 10.9 64-bit
- Windows XP 32-bit
- Linux
Before we begin, we will need the following ingredients: A Linux Box. If you already have a Linux box, you are more than welcome to use it. If you don’t have one around, you may consider to grab a spare machine and install a Linux. The machine does not need to be very powerful. In my case, I use a Pentium 4 (1 GB ram) desktop which was born in 2004. You can go to local university / library / recycle center to get one. They usually sell it for very low price (below $30) or sometimes give away for free.
Install the HP Printer Driver
In this tutorial, I am going to use CentOS as an example. CentOS is a free version of Red Hat. You can use other Linux such as RHEL, Fedora, Scientific Linux etc. The reason why I prefer CentOS because of its stability and long term support. It is stable and I will be able to update the system for at least 7 years.
Before we begin, we want to make sure that the USB version 1 is available. Simply go to the BIOS and make sure that your system supports the legacy USB (i.e., USB 1). Since HP LaserJet 1000 uses USB 1, and some manufacturers disable the USB 1 settings by default, we want to enable them.
So after installing CentOS, we need to do the following:
#The default repository of CentOS is very limited. Let's add a more powerful one: sudo rpm -Uvh http://linux.mirrors.es.net/fedora-epel/6/x86_64/epel-release-6-8.noarch.rpm sudo rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm sudo yum update --enablerepo=remi,remi-test
The following tutorial is based on this page. Depending on your hardware, I notice that the tutorial is not 100% working. You may want to follow my version below. Before we start, I encourage you to open this page first, and keep the current page side-by-side for reference.
#Install the developer tools sudo yum groupinstall "Development Tools" sudo yum install kernel-devel kernel-headers #Install the HP printer and related sudo yum install hplip hplip-gui hplip-libs #Install the avahi daemon sudo yum install avahi sudo service avahi-daemon start #Install the libraries required by hp sudo yum install cups cups-devel gcc-c++ ghostscript libjpeg-devel glibc-headers libtool libusb-devel make python python-devel PyXML openssl-devel net-snmp-devel policycoreutils-gui PyQt PyQt-devel dbus-python notify-python sane-backends sane-backends-devel sane-frontends xsane python-imaging python-imaging-devel #Depending on your HP printer. If your printer is old enough and use USB 1, you may want to install the following: Install some hardware-related libraries sudo yum install avahi-tools libusb1-devel libusb1 dbus dbus-devel libsane-hpaio #Install the following chemicals: sudo rpm -ev --nodeps libsane-hpaio sudo rpm -ev hplip-gui sudo rpm -ev hplip sudo rpm -ev hpijs
Disable the SELinux. It’s like the Windows Firewall. A fancy looking crap which does nothing useful except causing lots of trouble.
sudo nano /etc/selinux/config SELINUX=disabled
Now, visit here to get the latest version of HP software. Go to the latest directory and download the gz file. In the following, I will assume that the version is: 3.14.6, i.e., hplip-3.14.6.tar.gz. You may want to adjust the version.
Of course, we need to extract it.
tar xvfz hplip-3.14.6.tar.gz cd hplip-3.14.6
Now, go to this page and head to step 5. Try to find the corresponding command to install HPLIP. In my case, I am using CentOS 6.5 64-bit, so my command will be:
./configure --with-hpppddir=/usr/share/cups/model/HP --libdir=/usr/lib64 --prefix=/usr --enable-qt4 --disable-libusb01_build --enable-doc-build --enable-cups-ppd-install --disable-foomatic-drv-install --disable-foomatic-ppd-install --disable-hpijs-install --disable-udev_sysfs_rules --disable-policykit --disable-cups-drv-install --enable-hpcups-install --enable-network-build --enable-dbus-build --enable-scan-build --enable-fax-build
In case you got error (such as missing libraries), try to run the following for trouble-shooting:
./check.py
Now, let’s compile the source. You may want to run the make as a regular user.
make
And we are ready to install it!
sudo make install
Oh, we need to add some important users as well:
su -c "/usr/sbin/usermod -a -G lp,sys $USER"
Time to reboot the computer:
sudo reboot
Now, log in to the desktop / graphic mode. We need to use the HP tool to set up the printer. Open the terminal within the CentOS graphic interface.
sudo hp-setup
Just following the instructions. It is very simple. Click here if you need help.
Now, let’s open the printer settings. You can either go to System –> Admin –> Printing, or run the following:
system-config-printer
Find your printer, open the property and print a test page. If you see the actual printer, you are half way done.
Make the Printer Available On The Network
sudo service cups start
Also, remember to set the CUPS password:
sudo lppasswd -a admin
Now, we need to update the firewall settings:
sudo nano /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m udp -p udp --dport 631 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 631 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 443 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
and restart the firewall:
sudo service iptables restart
Now, let’s go to the following:
http://your_ip_address:631/printers/
Click your printer. In my case, mine is:
http://192.168.1.104:631/printers/hp_LaserJet_1000
Install the HP LaserJet 1000 on Windows 7/8 64-Bit
Now, go to Windows and add a printer. It’s a network printer. The corresponding location is:
http://192.168.1.104:631/printers/hp_LaserJet_1000
When it asks for the driver, try to use HP Laserjet 2300 PS. I found that this driver is pretty generic and it works great with my printer. After the installation is completed, try to print a test page. The idea will be similar in other operating systems, such as Windows XP and OS X.
Now your printer has a new life.
–Derrick
Our sponsors: