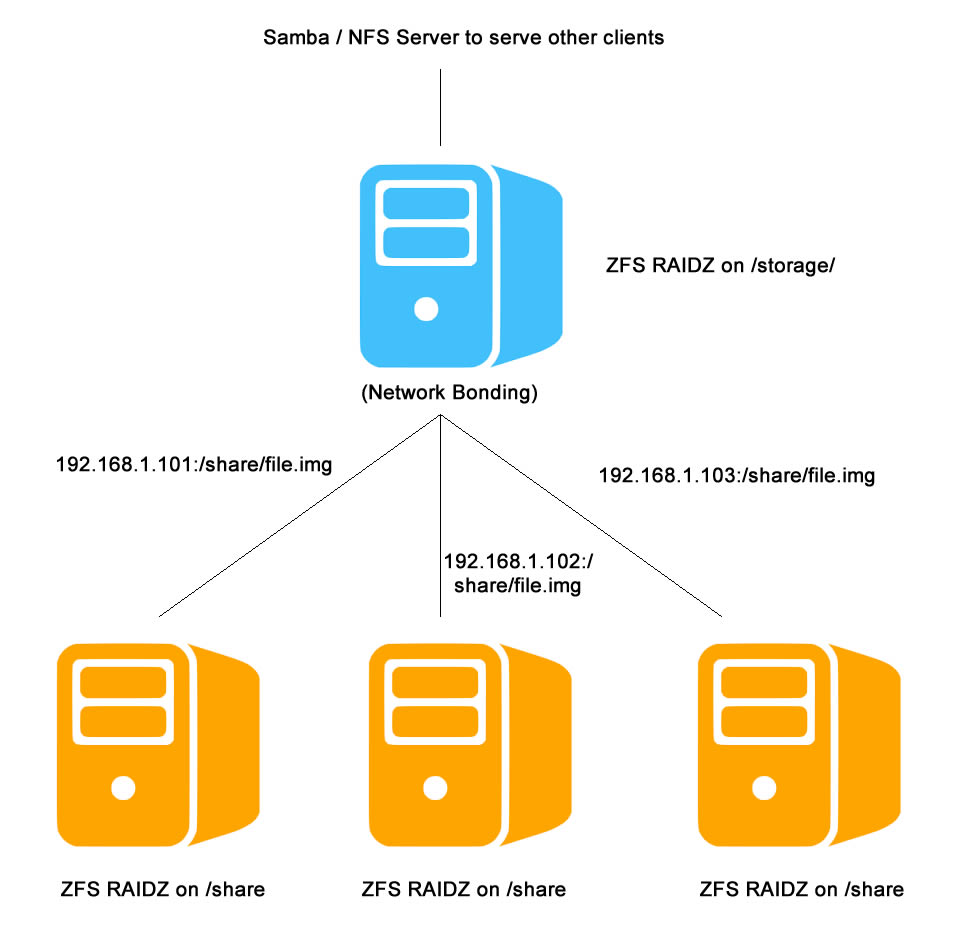
I always like to experimenting the idea of building a ZFS cluster, i.e., it has the robust of the ZFS with the cluster capacity. So I came up a test environment with this prototype. Keep in mind that this is just a proof of concept rather than a production-ready solution. I mainly want to test the idea of ZFS cluster.
The idea is pretty simple. Typically when we build the ZFS server, the members of the RAID are the hard drives. In my experiment, I use files instead of hard drives, where the corresponding files live in a network share (mounted via NFS). Since the bottle neck of the I/O will be limited by the network, I include a network bonding to increase the overall bandwidth.
The yellow servers are simply regular servers running ZFS with NFS service. I use the following command to generate a simple file / place holder for ZFS mounting:
#This will create an empty 1TB file, you can think of it as a 1TB hard drive / place holder. truncate -s 1000G file.img
Make sure that the corresponding NFS service is serving the file.img to the client (the blue server).
The blue server will be the NFS client of the yellow servers, where I will use it to serve the data to other computers. It has the following features:
It has a network bonding based on three Ethernet adapter:
#cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: adaptive load balancing Primary Slave: None Currently Active Slave: enp0s25 MII Status: up MII Polling Interval (ms): 1 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: enp0s25 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:19:d1:b2:1e:0d Slave queue ID: 0 Slave Interface: enp6s0 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:18:4d:f0:12:7b Slave queue ID: 0 Slave Interface: enp6s1 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:22:3f:f6:98:03 Slave queue ID: 0
It mounts the yellow servers via NFS
#df 192.168.1.101:/storage/share 25T 3.9T 21T 16% /nfs/192-168-1-101 192.168.1.102:/storage/share 8.1T 205G 7.9T 3% /nfs/192-168-1-102 192.168.1.103:/storage/share 8.3T 4.4T 4.0T 52% /nfs/192-168-1-103
The ZFS has the following structure:
#sudo zpool status
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
/nfs/192-168-1-101/file.img ONLINE 0 0 0
/nfs/192-168-1-102/file.img ONLINE 0 0 0
/nfs/192-168-1-103/file.img ONLINE 0 0 0
or:
zpool create -f storage raidz /nfs/192-168-1-101/file.img \
/nfs/192-168-1-102/file.img \
/nfs/192-168-1-103/file.img
The speed of the network will be the limitation of the system, I don’t expect the I/O speed goes beyond 375MB/s (125MB/s x 3). Also since it is a file-based ZFS (the ZFS on the blue server is based on files, not disks), so the overall performance will be discounted.
#Write speed time dd if=/dev/zero of=/storage/data/file.out bs=1M count=1000 1000+0 records in 1000+0 records out 1048576000 bytes (1.0 GB) copied, 3.6717 s, 285 MB/s
#Read speed time dd if=/storage/data/file.out of=/dev/null 1000+0 records in 1000+0 records out 1048576000 bytes (1.0 GB) copied, 3.9618 s, 265 MB/s
Both read and the write speed are roughly around 75% of the maximum bandwidth, which is not bad at all.
So I decide to make one of the yellow servers offline, let’s see what’s going on:
#sudo zpool status
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
/nfs/192-168-1-101/file.img ONLINE 0 0 0
/nfs/192-168-1-102/file.img ONLINE 0 0 0
/nfs/192-168-1-103/file.img UNAVAIL 0 0 0 cannot open
And the pool is still functioning, that’s pretty cool!
Here are some notes that will affect the overall performance:
- The quality of the Ethernet card matters, which includes PCIe or PCI, 1 lane or 16 lane, total throughput etc.
- The network traffic. Is the switch busy?
- How are you connect these servers together? One big switch or multiple switches that are bridged together. If they are bridged, the limitation will be the cable of the bridge, which is 125MB/s for gigabit network.
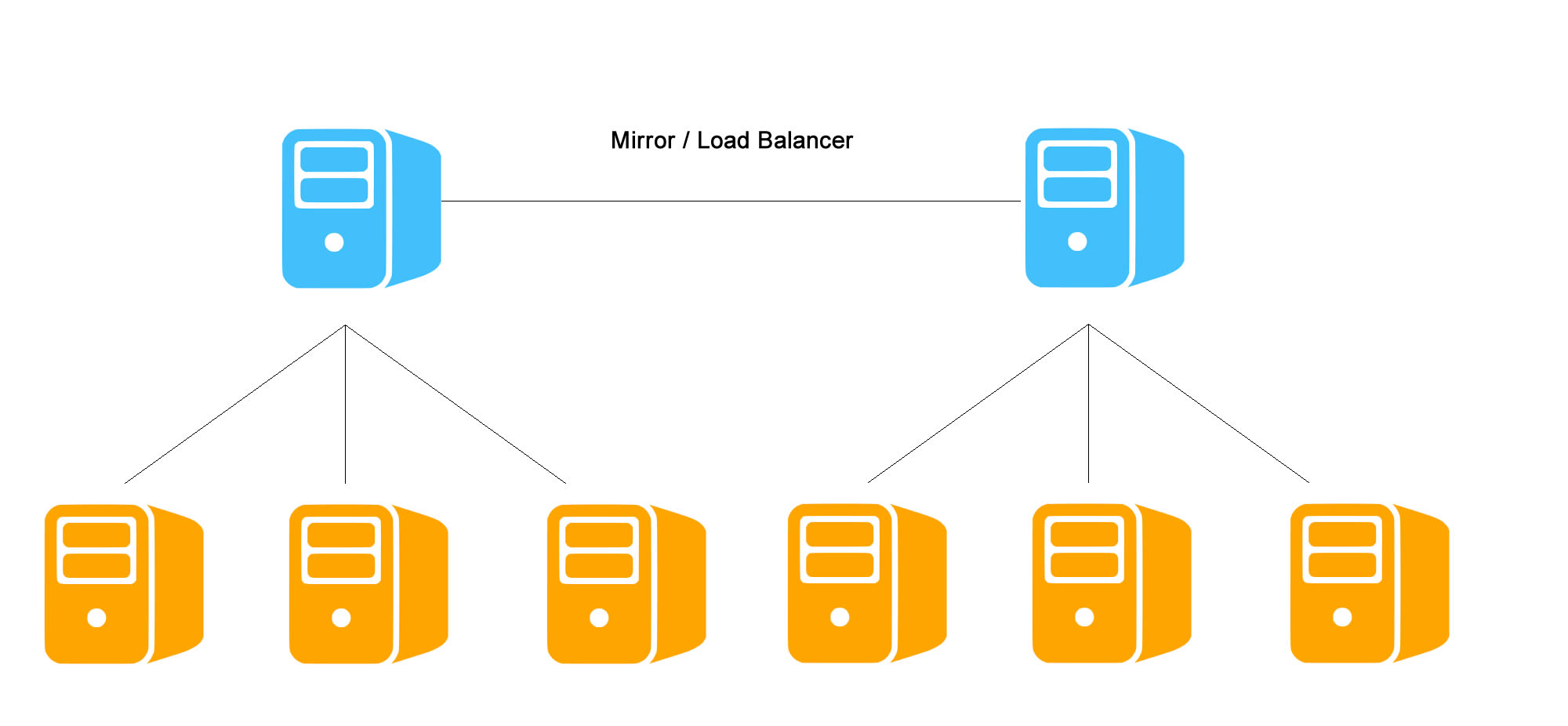
Again, this idea is just a proof of concept rather than for production purpose. If you decide to put this in a production environment, you may want to extend this idea further, such as:
Have fun!
Our sponsors:

There is no failover for the blue server if it goes down.
cluster means to eliminate all points of failure at least one redundancy
ZFS strength is direct attached disk replacing traditional Raid hardware not ZFS networking
this hole topology is weird.
This is a very simple layout which shows how ZFS can work at the network cluster level. In your situation, you can build a replicate of the blue server, which will load the same ZFS members underneath. You can even make your design more robust, but the technologies involved will be outside the scope of ZFS.
Nice setup Derrick, but as bouziri84 mention, to this solution be closer to clustered solution NAS Head (blue server) needs to be mirrored/in redundancy. This of course can be done on network level but how to easy setup fully redundancy cluster with zfs (1st option: without replicating data servers/yellow and 2nd option: with fully replicated data servers/yellow)…?
Thank you
I think you are comparing apple and orange. What you describe is highly available setup at the network / server level. This feature is not available in ZFS at all. ZFS only provides highly available feature at the hard drive level, i.e., it can handle fail-over if a disk is failed. If the failure happens at the network level (e.g., switch is dead) or server level (e.g., loss of power), standard ZFS (one server setup with direct attached disks) won’t be able to handle this situation at all. So it is not fair to talk about a feature that standard ZFS does not offer.
Let’s go back to your question. It is very easy to implement highly available feature at the server level. Many software packages such as Corosync, Pacemaker can implement the fail over on top of NFS at the server level. Notice that it only takes care of the server level. It doesn’t cover the network level (a router/switch is dead and the IP addresses are messed up) failure. As you see, if you want to create a complete fail-proof system, you will need to take care of many parts, including network, power, cluster, server etc. ZFS only plays a small part in this big picture. It is not fair to ask ZFS to work on something outside its scope.